01算法复杂度
1.1什么叫数据结构和算法
数据结构(data structure)是用来存放和管理(比如插入,删除,查找,更新,遍历等)各种数据的一种程序结构,常见的数据结构有数组,链表,队列,栈,树,HASH表,图等。
算法(algorithm)是指解决一个问题的方法及其实现。算法可以理解为由基本运算及规定的运算顺序所构成的完整的解题步骤。比如各种排序方法,折半查找等都是常见的算法。
算法好坏的判断标准包括时间复杂度和空间复杂度两个方面。下面依次介绍时间复杂度和空间复杂度。
1.2 时间复杂度
算法的时间复杂度是指执行算法所需要的计算工作量。一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度,记为T(n),其中n为问题规模。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数。如T(n)=4n^2+5n,或者8n^2+1,那么时间复杂度都为:O(n^2),取最高幂,并去掉系数。
常见的时间复杂度有:常数阶O(1),对数阶O(logn),线性阶O(n), 线性对数阶O(nlogn),平方阶O(n^2),立方阶O(n^3),..., k次方阶O(n^k),指数阶O(2^n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。也就是从效率上来看,他们的优劣比较如下:
O(1)>O(logn)>O(nlogn)>O(n2)>O(n3)>O(2n)
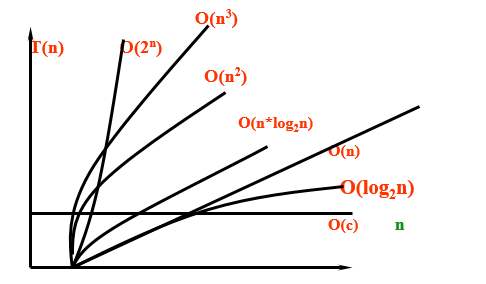
在计算时间复杂度的时候,先找出算法的基本操作,然后根据相应的各语句确定它的执行次数,再找出 T(n) 的同数量级(它的同数量级有以下:1,logn,n,n logn ,n的平方,n的三次方,2的n次方,n!),找出后,f(n) = 该数量级,若 T(n)/f(n) 求极限可得到一常数c,则时间复杂度T(n) = O(f(n))
看看下面的程序时间复杂度:
int max(int x, int y)
{
return x>y?x:y;
}
该程序的基本操作为:x>y?x:y。每次执行一次。所以,它的时间复杂度为O(1)
再看看下面的程序的时间复杂度:
for (i=1;i<=n;++i)
{
for (j=1;j<=n;++j)
{
c[i][j]=0; //该步骤属于基本操作 执行次数:n的平方
for (k=1;k<=n;++k)
c[i][j] += a[i][k]*b[k][j]; //该步骤属于基本操作 执行次数:n的三次方
}
}
因此,T(n)=n^3+n^2
取表达式中次数最大的,并且去掉常数,因此时间复杂度为:O(n^3)
时间复杂度计算的一般方法是:看看有几重for循环,只有一重则时间复杂度为O(n),二重则为O(n^2),依此类推,如果有二分则为O(logn),二分例如快速排序、二分查找,如果一个for循环套一个二分,那么时间复杂度则为O(nlogn)
按照该方法,那么下面的冒泡排序算法的时间复杂度为O(n2)
void bubblesort(int a[], int n)
{
int i, j, tmp;
for (i = 0; i < n-1; i++)
{
for (j = n-1; j >= i+1; j--)
{
if (a[j] < a[j-1])
{
tmp = a[j];
a[j] = a[j-1];
a[j-1] = tmp;
}
}
}
}
1.3 空间复杂度
算法的空间复杂度是指算法需要消耗的内存空间。其计算和表示方法与时间复杂度类似,一般都用复杂度的渐近性来表示。同时间复杂度相比,空间复杂度的分析要简单得多。程序在运行时候动态分配的空间,以及递归栈所需的空间等。这部分的空间大小与算法有关。而那些静态的空间,比如代码,常量以及简单的变量与空间复杂度无关。
比较下面的程序1和程序2:
程序1:
void reversestr(char *str, int len)
{
for(int i = 0; i < len/2;i++)
{
char tmp;
tmp = str[i];
str[i] = str[len-i-1];
str[len-i-1] = tmp;
}
}
程序2:
char * reversestr(char *str, int len)
{
char *strnew = (char *) malloc(len+1);
if (strnew == NULL)
{
return NULL;
}
memset(strnew, 0, len+1);
int pos = 0;
for(int i = len-1; i >=0; i--)
{
strnew[pos++]= str[i];
}
return strnew;
}
程序1和程序2实现的功能都是将一个输入的字符串进行逆置,比如”hello world”逆置为”dlrow olleh”。程序1在计算过程中,只申请了一个临时变量tmp,因此它的空间复杂度为O(1);程序2则在计算过程中,动态分配了一个内存,而且该内存大小与输入字符串长度成正比,因此该算法的空间复杂度为O(n)。
再看下面这个算法:找出所有数中重复的数,这些数范围都在0与65536之间。
#define MAXMUM 65536
void FindRepeated(int a[], int n)
{
int tmp[MAXMUM];//定义一个局部数组,用来计算数组a[]中重复的数的次数
int i;
for (i = 0; i < MAXMUM; i++)
{
tmp[i] = 0;
}
for (i = 0; i < n; i ++)
{
tmp[a[i]]++;//数组a[]中的元素,在tmp[]中重复一次,加1
}
for (i = 0; i < MAXMUM; i++)
{
if (tmp[i]>1)//如果tmp[i]的值大于1,那么i就是数组a[]中重复的数
printf(“%d”, i);
}
}
那么,上面的代码的空间复杂度是多少呢?答案是:O(1)。尽管在计算过程中,程序在栈上分配了tmp[MAXMUM]这么大的一个空间,但由于它的大小是常量,不会随着问题的规模扩大而变大,因此空间复杂度就是O(1)。>p
本页共113段,3316个字符,5979 Byte(字节)